Para outras páxinas con títulos homónimos véxase:
Distribución.
Log-normal
Función de densidade

μ=0
|
Función de distribución
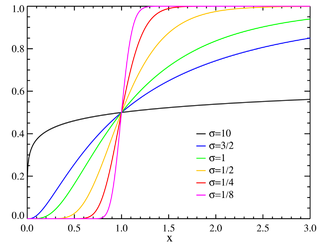
μ=0
|
| Parámetros
|


|
| Soporte
|

|
| Función de densidade
|
![{\displaystyle {\frac {e^{-[{\frac {\ln(x)-\mu }{\sigma }}]^{2}/2]}}{x\sigma {\sqrt {2\pi }}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c12c2a0e4591a0466e74d9b9db8e8010567fb04f)
|
| Función de distribución
|
![{\displaystyle {\frac {1}{2}}+{\frac {1}{2}}\mathrm {Erf} \left[{\frac {\ln(x)-\mu }{\sigma {\sqrt {2}}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1a9d6e18da5576e1e9e9ebfb992655a16fd71de4)
|
| Media
|

|
| Mediana
|

|
| Moda
|

|
| Varianza
|

|
| Asimetría
|

|
| Curtose
|

|
| Entropía
|

|
| F. xeradora de momentos
|
(ver no texto os momentos)
|
| Func. caract.
|
|
En probabilidade e estatística, a distribución log-normal é a distribución de probabilidade de calquera variable aleatoria con seu logaritmo normalmente distribuído (a base da función logarítmica non é importante xa que se loga X está distribuída normalmente se e só se logb X está distribuída normalmente). Se X é unha variable aleatoria cunha distribución normal, entón exp(X) ten unha distribución log-normal.
"Log-normal" tamén se escribe "log normal" ou "lognormal".
Unha variable pode ser modelada como log-normal se pode ser considerada como o produto multiplicativo de moitos pequenos factores independentes. Un exemplo típico é o retorno a longo prazo dunha inversión nunha acción: pódese considerar como o produto dos retornos diarios.
A distribución log-normal ten a función densidade de probabilidade

para  , onde
, onde  e
e  son a media e o desvío estándar do logaritmo da variable. O valor esperado é
son a media e o desvío estándar do logaritmo da variable. O valor esperado é

e a varianza é
 .
.
Relación coa media e o desvío estándar xeométrico[editar | editar a fonte]
A distribución log-normal, a media xeométrica, e o desvío estándar xeométrico están relacionadas. Neste caso, a media xeométrica é igual a  e o desvío estándar xeométrico é igual a
e o desvío estándar xeométrico é igual a .
.
Se unha mostra de datos determinase que provén dunha poboación distribuída seguindo unha log-normal, a media xeométrica e o desvío estándar xeométrico pódense utilizar para estimar os intervalos de confianza tal como a media aritmética e o desvío estándar se usan para estimar os intervalos de confianza para un dato distribuído normalmente.
| Límite do intervalo de confianza
|
espazo log
|
xeométrica
|
| 3σ límite inferior
|

|

|
| 2σ límite inferior
|

|

|
| 1σ límite inferior
|

|

|
| 1σ límite superior
|

|

|
| 2σ límite superior
|

|

|
| 3σ límite superior
|

|

|
Onde a media xeométrica  e o desvío estándar xeométrico
e o desvío estándar xeométrico 
Os primeiros momentos son:




ou de forma xeral:

Para determina-los estimadores que máis aproximan os parámetros μ e σ da distribución log-normal, podemos utilizar o mesmo procedemento que para a distribución normal. Para non repetilo, obsérvese que

onde por  denotamos a función de densidade de probabilidade da distribución log-normal, e por
denotamos a función de densidade de probabilidade da distribución log-normal, e por  — a da distribución normal. Polo tanto, utilizando os memos índices para denotar as distribucións, podemos escribir que
— a da distribución normal. Polo tanto, utilizando os memos índices para denotar as distribucións, podemos escribir que

Xa que o primeiro termo é constante respecto a μ e σ, ambas funcións logarítmicas,  e
e  , obteñen o seu máximo co mesmo μ e σ. Polo tanto, utilizando as fórmulas para os estimadores dos parámetros da distribución normal, e a inigualdade de arriba, deducimos que para a distribución log-normal cúmprese
, obteñen o seu máximo co mesmo μ e σ. Polo tanto, utilizando as fórmulas para os estimadores dos parámetros da distribución normal, e a inigualdade de arriba, deducimos que para a distribución log-normal cúmprese

 é unha distribución normal se
é unha distribución normal se  e
e  .
.- Se
 son variables independentes log-normalmente distribuídas co mesmo parámetro μ e permitindo que varie σ, e
son variables independentes log-normalmente distribuídas co mesmo parámetro μ e permitindo que varie σ, e  , entón Y é unha variable distribuída log-normalmente como:
, entón Y é unha variable distribuída log-normalmente como:  .
.


